 sauvegarde
sauvegarde
Contrairement à la croyance populaire selon laquelle tout ce qui est en ligne reste en ligne, Internet ne se souvient pas de tout. Dans un précédent article de cette série, nous avons examiné pas moins de neuf scénarios dans lesquels vous pourriez perdre l’accès à des contenus en ligne. Nous avons également fourni un guide détaillé sur les informations que vous devez absolument (et de préférence rapidement) sauvegarder sur votre ordinateur et sur les façons de le faire. Aujourd’hui, nous verrons comment enregistrer facilement des pages Web sur votre ordinateur, comment organiser ces archives et que faire si votre site préféré a disparu.
Imaginons que vous souhaitiez enregistrer un article de blog contenant une recette, compiler une bibliographie pour votre mémoire de recherche ou même conserver une publication en ligne pour des raisons juridiques. Tous ces contenus sont publiés sous forme de pages Web, qui ont tendance à disparaître au mauvais moment. Vous voulez vous remémorer l’actualité musicale et les ragots de 2005 ? Bonne chance : le site MTV News a fermé et tous ses articles et interviews ne sont plus disponibles. Vous voulez consulter des liens Wikipédia ? 11 % d’entre eux ne mènent nulle part, alors qu’ils fonctionnaient au moment de la publication de l’article. Ce phénomène de « pourriture des liens », c’est-à-dire la suppression ou le déplacement progressifs de contenus en ligne, est en train de devenir un problème majeur. 38 % des pages qui existaient il y a dix ans ne sont plus accessibles aujourd’hui. Par conséquent, si une page Web vous intéresse ou si vous en avez besoin, il est judicieux d’en créer une copie de sauvegarde.
Comment enregistrer une page Web sur votre ordinateur
Étant donné qu’une page Web se compose de dizaines, voire de centaines de fichiers, la sauvegarder demandera un certain effort. Voici les principales façons de procéder :
Enregistrez uniquement le texte dans un fichier HTML. Sélectionnez la commande de menu ou le bouton « Enregistrer la page sous… » dans votre navigateur, puis sélectionnez » Page Web, HTML uniquement « . Vous n’enregistrerez que le texte de la page Web, sans aucun élément graphique ou autre.
Enregistrez le texte et les images. L’option » Page Web complète » créera, outre un fichier HTML, un dossier portant le même nom et contenant tous les éléments graphiques, les styles et les scripts de la page. L’inconvénient de cette option est que l’enregistrement d’un grand nombre de fichiers auxiliaires encombre votre disque dur. Plus pratique, l’option « Page Web, fichier unique » regroupe la page Web et toutes ses ressources dans un seul fichier .mhtml. Celui-ci s’ouvrira sans problème dans Chrome et Edge, mais d’autres navigateurs peuvent poser des problèmes. Cette option n’est pas disponible dans tous les navigateurs, mais si vous installez l’extension SingleFile (disponible pour la plupart des navigateurs), vous pouvez enregistrer la page Web entière et son contenu multimédia sous la forme d’un seul fichier HTML qui s’ouvre parfaitement dans tous les navigateurs modernes.
Imprimez le contenu au format PDF. Pour conserver le contenu principal de la page, mais éliminer les menus et les bannières, la meilleure option est d’imprimer le contenu au format PDF. Le fichier obtenu s’ouvre sur n’importe quel ordinateur.
Quelle que soit l’option choisie, assurez-vous que le texte principal que vous souhaitez conserver est toujours lisible lorsque vous ouvrez le document.
Une façon plus simple d’enregistrer une page Web
Les méthodes décrites ci-dessus prennent un peu de temps et encombrent votre disque dur. Pour plus de facilité, utilisez un service dédié, comme Pocket (anciennement Read It Later), wallabag ou Raindrop.io. Ils fonctionnent tous de la même manière : vous envoyez un lien à partir duquel le service récupère un document avec toutes les illustrations, nettoie la page de tout ce qui n’est pas nécessaire et l’enregistre dans votre espace de stockage personnel en ligne. Même si la page d’origine est supprimée ou modifiée, la version que vous souhaitez conserver restera dans vos archives. Ces services vous permettent de regrouper et de trier vos liens, de rechercher du texte à l’intérieur et de consulter vos pages enregistrées sur n’importe quel appareil. Pour les ordinateurs de bureau, une extension est disponible pour tous les principaux navigateurs, et pour les téléphones portables, il existe une application.
Tous ces services proposent des archives « éternelles » uniquement dans le cadre d’un abonnement premium, ce qui signifie que vous devrez payer pour cette facilité. Cela dit, Wallabag est un logiciel libre. Vous pouvez donc l’installer sur votre propre serveur sans avoir à payer pour des services tiers ni à vous soucier de la fermeture du service.
Certaines applications de prise de notes permettent également d’enregistrer des pages Web complètes. Il s’agit notamment d’Evernote, où la fonctionnalité s’appelle « Web Clipper ».
Comment sauvegarder une page Web pour d’autres personnes
Si vous avez besoin non seulement d’une copie pour vous-même, mais aussi de partager une version précise de la page avec d’autres personnes, vous aurez besoin d’un service d’archivage public.
Le plus connu est l’Internet Archive (archive.org) et sa Wayback Machine. Il existe également d’autres options : archive.today (alias archive.is), perma.cc et megalodon.jp. Ils fonctionnent selon le même principe : à la demande de l’utilisateur ou automatiquement, ils visitent des pages Web et en enregistrent une copie sur leurs serveurs.
Pour demander l’archivage d’une page Web, rendez-vous sur le site web.archive.org et saisissez l’adresse complète dans le champ Save Page Now. Après avoir cliqué sur Save page, une fenêtre décrivant tous les composants chargés de la page apparaît, suivie d’un lien permanent vers le site dans son état préservé. Voici un exemple : https://web.archive.org/web/20240918234814/https://www.kaspersky.com/blog. Le lien indique à la fois l’adresse de la page enregistrée et l’heure exacte de l’enregistrement, ce qui est parfait à des fins d’archivage.
L’enregistrement sur archive.org vous permet de gérer une collection de liens de ce type, de faire des captures d’écran des sites enregistrés et de télécharger des copies de ces sites dans le format spécial d’archivage Web WACZ.
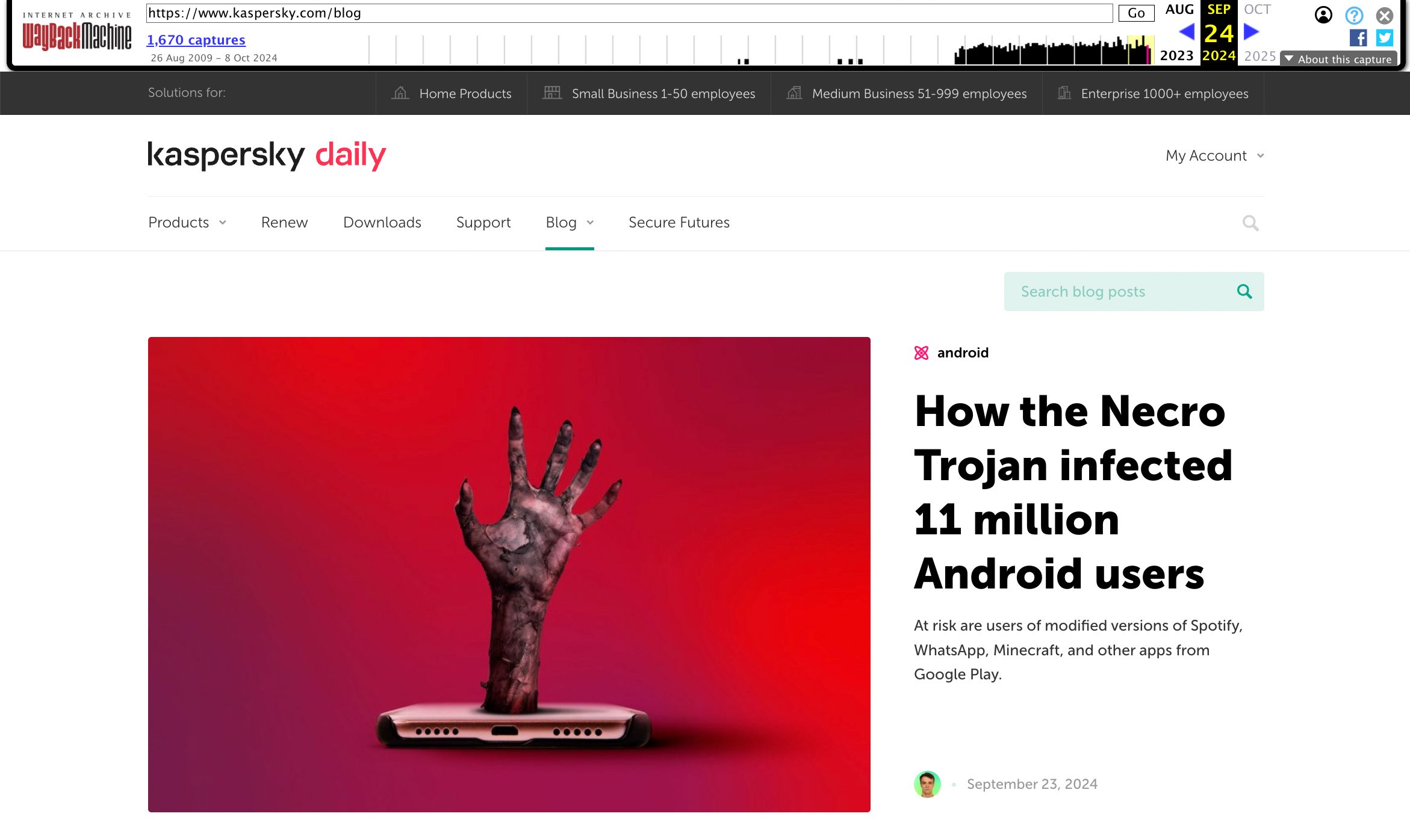
Sur le site archive.org, vous pouvez consulter les versions antérieures des sites Web et sauvegarder l’état actuel de n’importe quel site, par exemple, de notre blog
En ouvrant le lien vers l’archive, vous verrez la page sauvegardée accompagnée d’un horodatage indiquant la date à laquelle l’instantané a été pris. Cette fonction est utile pour suivre et documenter toute modification apportée aux données d’un site Web : fluctuations de prix, mises à jour de la description des produits, édition de bulletins d’information et suppression d’informations. Ce dernier point est particulièrement important pour les chercheurs historiques et culturels qui travaillent sur des sites Web disparus. Ci-dessous, vous pouvez voir l’une des premières versions de GeoCities, un service d’hébergement Web autrefois très populaire qui vous permettait de créer des « pages d’accueil », de vous exprimer et de trouver des amis partageant les mêmes centres d’intérêt, bien avant les réseaux sociaux. Ce n’est que grâce à la Wayback Machine que nous pouvons le voir aujourd’hui. En effet, le site a fermé ses portes en 2016.
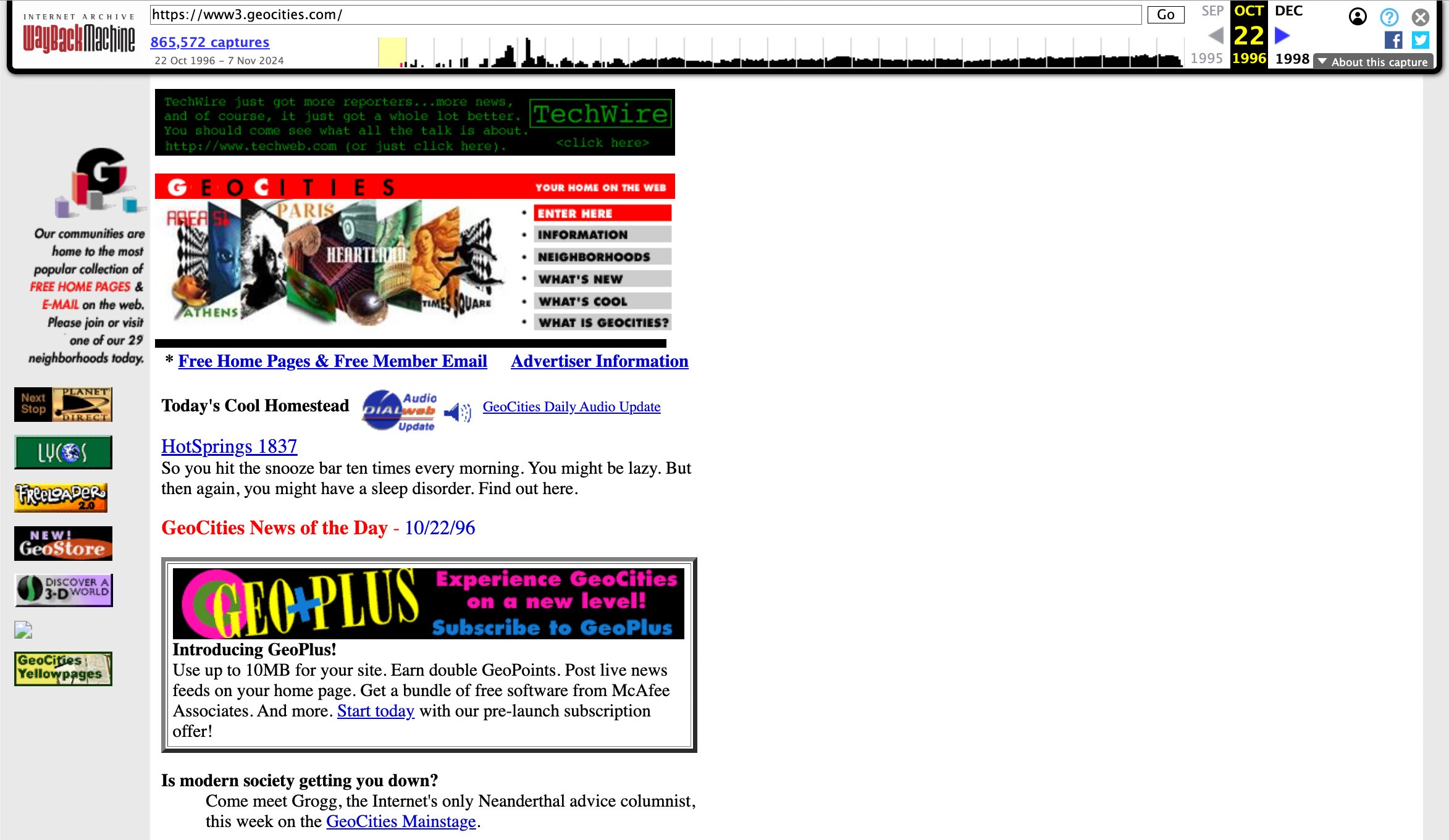
Un cadeau pour les anciens : l’une des premières versions de GeoCities.com
Comment retrouver un contenu Internet supprimé ou une ancienne version d’un site Web ?
Pour consulter l’ancienne version de n’importe quel site Internet, procédez comme suit :
- Ouvrez le site archive.org.
- Saisissez l’adresse complète du site Web ou d’une page spécifique dans la case située à côté du logo et cliquez sur Entrée. Si l’URL exacte est inconnue, vous pouvez saisir le nom du site Web ou des mots qui le décrivent bien.
- Sélectionnez le site Web souhaité dans la liste. Les résultats montrent tout de suite combien de copies sont archivées et pour quelle période.
- Utilisez le calendrier pour sélectionner les copies sauvegardées du site que vous souhaitez consulter. Les dates pour lesquelles il existe une copie sauvegardée sont entourées : plus le cercle est grand, plus le nombre de copies effectuées ce jour-là est élevé.
- Cliquez sur la date souhaitée et inspectez le site sauvegardé. Notez que le chargement d’une copie de l’archive peut prendre quelques minutes.
- Le calendrier graphique au-dessus de la copie du site vous permet de naviguer entre les copies plus anciennes et plus récentes.
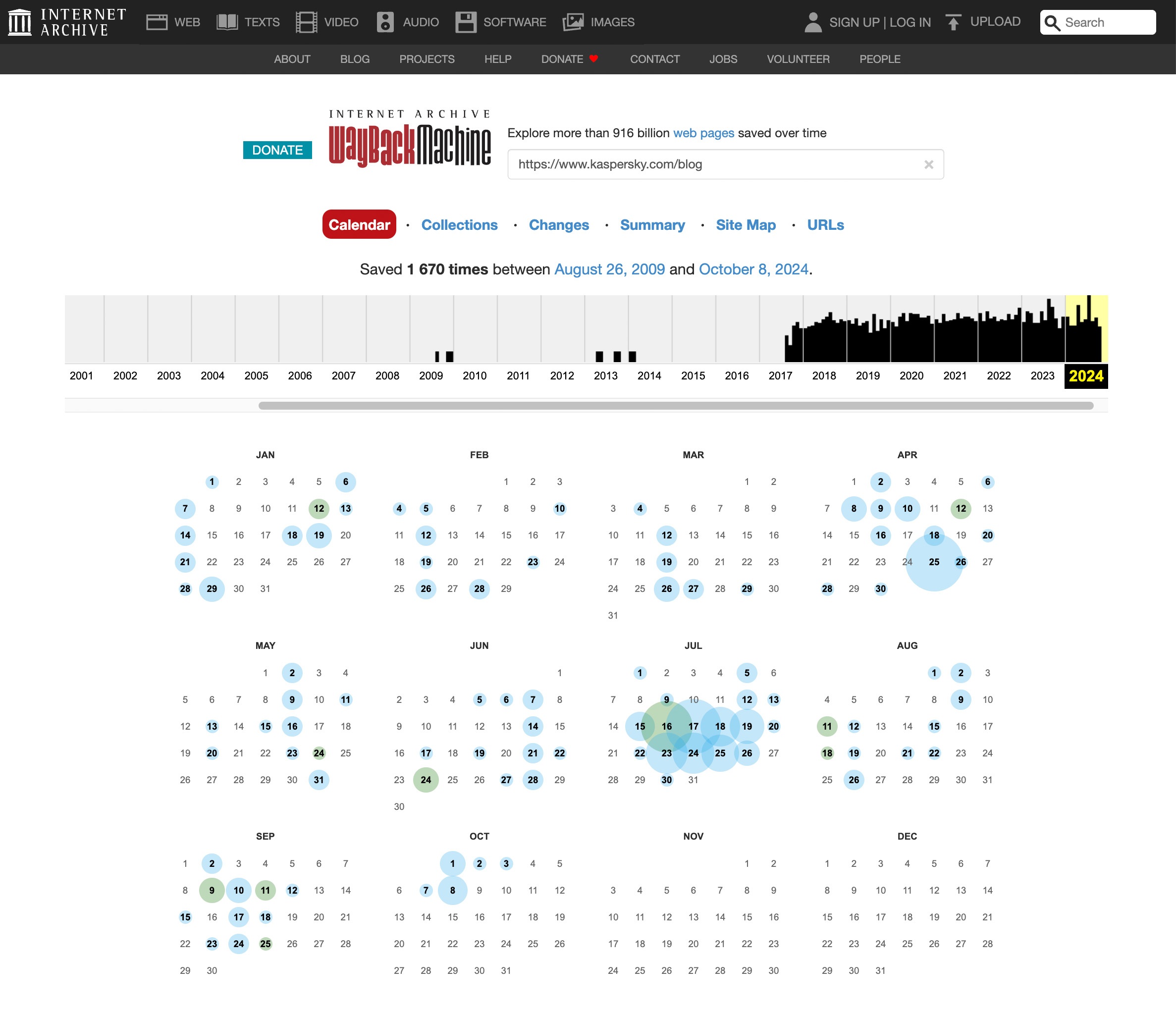
Comment explorer d’anciennes versions de sites sur web.archive.org
Vous pouvez copier le lien vers la copie récupérée dans la barre d’adresse pour accéder directement au site archivé, sans passer par l’interface de recherche.
Que faire si le site archive.org ne répond pas à vos attentes ?
La fondation archive.org se conforme parfois aux demandes des détenteurs de droits d’auteur et d’autres parties autorisées d’exclure certains sites de la Wayback Machine. En outre, le service n’a jamais eu pour objectif de préserver l’intégralité du réseau Internet. Il se peut donc que la page dont vous avez besoin n’ait jamais été indexée. Le cas échéant, essayez de rechercher le site dans d’autres capsules temporelles.
Archive.today (alias archive.is) n’enregistre pas automatiquement les pages, mais uniquement à la demande des utilisateurs. Cela permet notamment de ne pas avoir à suivre les instructions pour les robots de recherche (robots.txt), et signifie que l’archive contient des documents qui ne sont pas disponibles dans la Wayback Machine.
Un autre projet important d’archivage sur le Web est perma.cc, créé par un consortium de grandes bibliothèques mondiales. Cependant, ce service n’est gratuit que pour les organisations participantes. Les utilisateurs individuels peuvent souscrire un abonnement payant, dont le prix dépend du nombre de liens archivés.
Le contenu mis en cache par les moteurs de recherche constitue une alternative efficace aux services d’archivage spécialisés. Pour indexer les pages Web, les moteurs de recherche récupèrent leur texte, ce qui permet de trouver une version brute mais lisible de presque toutes les pages. Pendant longtemps, le cache de Google est resté le plus accessible, mais début 2024, le géant de la recherche a supprimé les liens directs vers son cache dans les résultats de recherche. Le service fonctionne toujours, mais il est très difficile d’y accéder directement.
Il est donc préférable d’utiliser des extensions de navigateur qui facilitent l’utilisation des archives Internet. Par exemple, si un lien vous dirige vers une page supprimée ou un site Web disparu, l’extension Web Archives vous redirige directement vers une copie archivée de cette page sur web.archive.org, archive.today ou perma.cc, ou affiche une version mise en cache de cette page à partir de Google, Bing ou Yandex.
Comment enregistrer des données provenant d’autres services en ligne ?
Outre les pages Web, il existe de nombreux autres services en ligne, allant des albums photos aux réseaux sociaux en passant par les notes, qui contiennent des données que vous pourriez également vouloir sauvegarder. Bien entendu, les recommandations varient en fonction des types de données et des services concernés, mais pour vous faciliter la tâche, nous avons regroupé toutes les instructions correspondantes sous la balise « sauvegarde ». Vous pouvez vous renseigner sur la création de sauvegardes pour :
Et n’oubliez pas de protéger vos sauvegardes contre les ransomwares et les logiciels espions !

 Conseils
Conseils