 AI
AI
Des chercheurs israéliens de l’Offensive AI Lab ont publié un article présentant une méthode qui permet de reconstituer le texte de messages interceptés depuis un chatbot d’IA. Aujourd’hui, nous allons voir comment une telle attaque fonctionne et à quel point elle peut s’avérer dangereuse.
Quelles informations peuvent être extraites des messages interceptés depuis un chatbot d’IA ?
Naturellement, les chatbots envoient leurs messages sous forme chiffrée. Cependant, la mise en œuvre de grands modèles de langage (LLM), de même que les chatbots développés à partir de ces modèles, comporte un certain nombre de fonctionnalités qui affaiblissent sérieusement le chiffrement. Combinées, ces fonctionnalités facilitent l’exécution d’une attaque par canal auxiliaire, dans la mesure où le contenu d’un message est reconstitué à partir de fragments d’informations ayant fait l’objet d’une fuite de données.
Pour comprendre ce qui se passe lors d’une telle attaque, il convient de plonger un peu plus en détail dans la mécanique des LLM et des chatbots. La première chose à savoir est que les LLM ne fonctionnent pas à partir de caractères ou de mots isolés spécifiques, mais à partir de jetons qui peuvent être considérés comme des unités de texte sémantiques. La page Tokenizer du site Internet d’OpenAI donne un aperçu de leur fonctionnement interne.

Cet exemple montre comment fonctionne la tokenisation de messages avec les modèles GPT-3.5 et GPT-4. Source
La deuxième fonctionnalité qui facilite ce type d’attaque est une caractéristique que vous connaissez bien si vous avez déjà interagi avec des chatbots d’IA : ces derniers n’envoient pas de réponses en un seul gros bloc, mais répondent petit à petit, un peu comme si une personne écrivait. Cependant, contrairement aux personnes, les LLM écrivent sous forme de jetons, et non sous forme de caractères isolés. Ainsi, les chatbots envoient les jetons générés en temps réel, les uns après les autres, à l’exception de Google Gemini qui s’avère par conséquent invulnérable à une telle attaque.
La troisième particularité est la suivante : au moment de la publication de l’article, la majeure partie des chatbots n’utilisaient pas la compression, l’encodage ou le remplissage (c’est-à-dire l’ajout de données parasites à un texte significatif afin de réduire la prévisibilité et d’augmenter la force du chiffrement) avant de chiffrer un message.
Les attaques par canal auxiliaire exploitent ces trois particularités. Même si les messages interceptés à partir d’un chatbot ne peuvent pas être déchiffrés, les pirates informatiques peuvent en extraire des données utiles, et en particulier la longueur de chaque jeton envoyé par le chatbot. Le résultat est semblable à une énigme de la Roue de la fortune : vous ne pouvez pas voir ce qui est précisément chiffré, mais la longueur des jetons de mots isolés est révélée.

S’il est impossible de déchiffrer le message, les pirates informatiques peuvent extraire la longueur des jetons envoyés par le chatbot, et la séquence obtenue est similaire à une phrase cachée du jeu télévisé la Roue de la fortune. Source
Utilisation des informations extraites pour reconstituer le texte du message
Il ne reste alors plus qu’à deviner les mots qui se cachent derrière les jetons. Et qui sont les plus grands experts en matière de devinettes ? Les LLM, bien sûr ! À vrai dire, il s’agit là de leur objectif premier : deviner les mots justes dans un contexte donné. Afin de reconstituer le texte du message d’origine à partir de la séquence de longueurs des jetons obtenue, les chercheurs se sont donc tournés vers un LLM…
Ou plutôt vers deux LLM, pour être précis, car ils ont remarqué que les premiers échanges dans les discussions avec des chatbots sont presque toujours des formules et que ces derniers sont donc facilement devinables par un modèle spécialement développé à partir d’un ensemble de premiers messages générés par des modèles de langage populaires. Ainsi, le premier modèle reconstitue les premiers messages, avant de les transmettre au second modèle qui prend en charge le reste de la discussion.

Schéma général de l’attaque. Source
Il en résulte un texte dans lequel les longueurs des jetons correspondent à celles du message d’origine. Cependant, les mots exacts sont reconstitués par force brute, avec plus ou moins de succès. Une correspondance parfaite entre le message reconstitué et le message d’origine est donc rare, car il arrive généralement qu’une partie du texte soit mal devinée. Parfois, le résultat est satisfaisant :

Dans cet exemple, le texte reconstitué est assez proche du texte d’origine. Source
Néanmoins, en cas d’échec, le texte reconstitué peut avoir peu d’éléments en commun avec le texte d’origine, voire aucun. Par exemple, le résultat peut être le suivant :

Ici, les suppositions laissent vraiment à désirer. Source
Le résultat peut même ressembler à ça :

Comme Winnie l’ourson l’a dit un jour, » On ne peut pas dire que tu aies raté, mais tu as raté le ballon « . Source
Au total, les chercheurs ont étudié plus d’une douzaine de chatbots d’IA et ont déterminé que la plupart d’entre eux étaient vulnérables à ce type d’attaque, à l’exception de Google Gemini (anciennement Bard) et de GitHub Copilot (à ne pas confondre avec Microsoft Copilot).
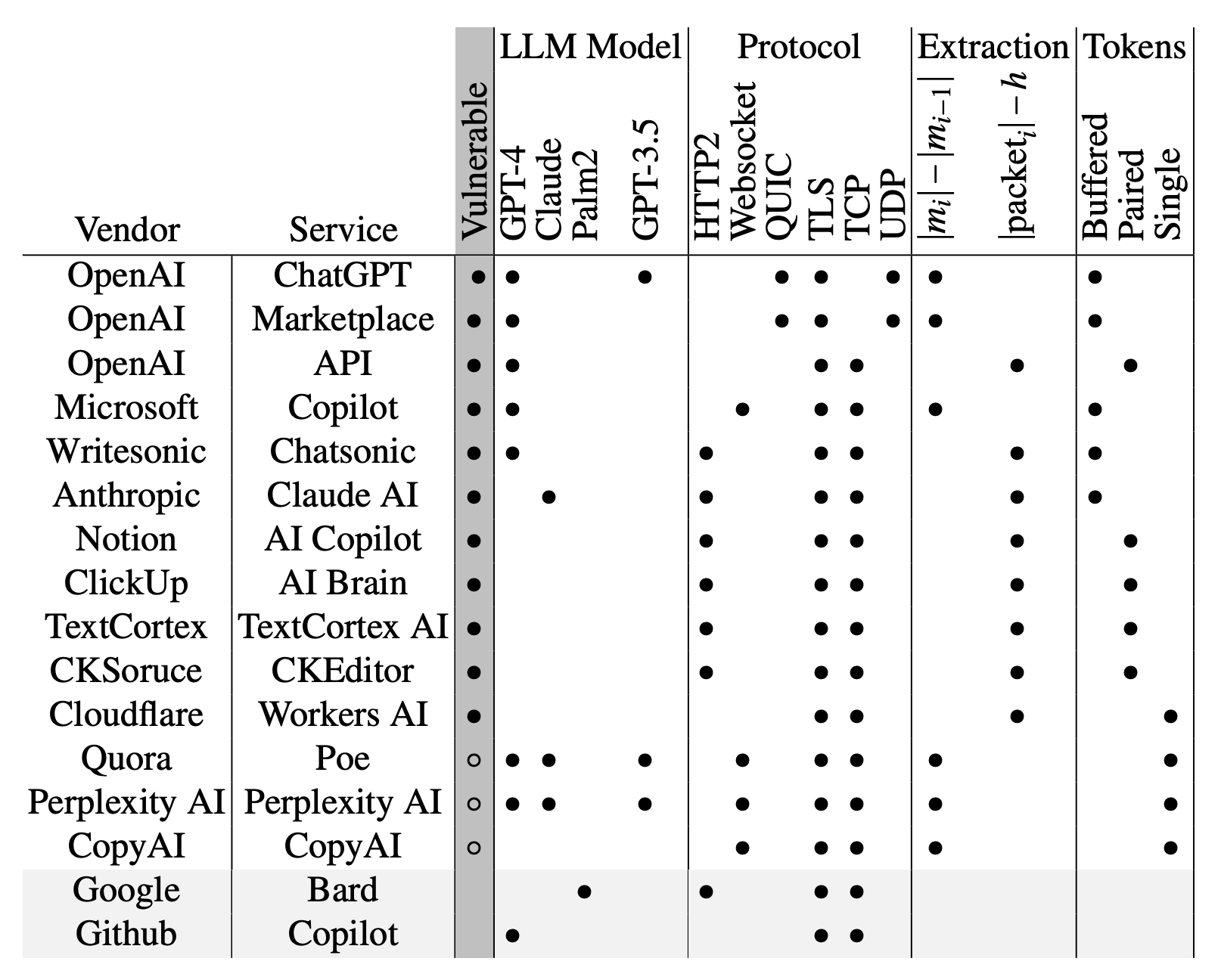
Au moment de la publication de l’article, de nombreux chatbots étaient vulnérables à ce type d’attaque. Source
Devrais-je m’inquiéter ?
Il convient de noter qu’une telle attaque est rétroactive. Supposons que quelqu’un se donne du mal pour intercepter et enregistrer vos discussions avec ChatGPT (ce qui n’est pas si facile, mais reste possible), dans lesquelles vous révélez de terribles secrets. Dans ce cas, en utilisant la méthode décrite ci-dessus, cette personne serait théoriquement capable de lire vos messages.
Heureusement, ses chances d’y parvenir ne sont pas très élevées : dans l’étude menée par les chercheurs, le sujet général de la conversation n’a en effet pu être déterminé que dans 55 % des cas. La reconstitution des messages, quant à elle, n’a été concluante que dans 29 % des cas. Il convient de souligner que les critères des chercheurs en matière de reconstitution parfaitement réussie ont été remplis, par exemple, dans les cas suivants :

Exemple de reconstitution de texte que les chercheurs ont jugée parfaitement réussie. Source
À vous de juger du degré d’importance de ces nuances sémantiques. Notez toutefois que cette méthode ne permet vraisemblablement pas d’extraire des informations particulières, comme des noms, des valeurs numériques, des dates, des adresses, des coordonnées et d’autres informations vitales, avec un degré de fiabilité quelconque.
Par ailleurs, ce type d’attaque connaît une autre limite que les chercheurs ont omis de mentionner : le succès de la reconstitution de texte dépend en grande partie de la langue dans laquelle les messages interceptés ont été écrits, car le succès de la tokenisation peut considérablement varier d’une langue à l’autre. Cet article s’est concentré sur l’anglais, caractérisé par des jetons très longs qui sont généralement équivalents à un mot entier. Par conséquent, le texte anglais tokenisé présente des caractéristiques spécifiques qui rendent la reconstitution relativement simple.
Aucune autre langue n’est comparable à l’anglais. Même les langues germaniques et romanes, qui sont les plus proches de l’anglais, ont une longueur de jetons moyenne 1,5 à 2 fois plus courte. Le russe, quant à lui, est 2,5 fois plus court : un jeton russe ordinaire ne comporte en effet que quelques caractères, ce qui réduit vraisemblablement à néant l’efficacité d’une telle attaque.
-

- Les textes dans différentes langues ont une tokenisation différente. Un exemple en anglais
-

- Les textes dans différentes langues ont une tokenisation différente. Un exemple en allemand
-

- Les textes dans différentes langues ont une tokenisation différente. Un exemple en russe
-

- Les textes dans différentes langues ont une tokenisation différente. Un exemple en hébreu
Au moins deux développeurs de chatbots d’IA, à savoir Cloudflare et OpenAI, ont d’ores et déjà réagi à l’article en intégrant la méthode de remplissage mentionnée ci-dessus, spécialement conçue pour répondre à ce type de menace. D’autres développeurs de chatbots d’IA devraient suivre le mouvement, de sorte que les communications futures avec les chatbots finiront par être, espérons-le, protégées contre ce type d’attaque.

 Conseils
Conseils